概念/概念定义
L1/L2/L3 分层记忆与经验召回
出自东方屹腾执行型 Agent 落地(案例提供 梁博)
概念定义
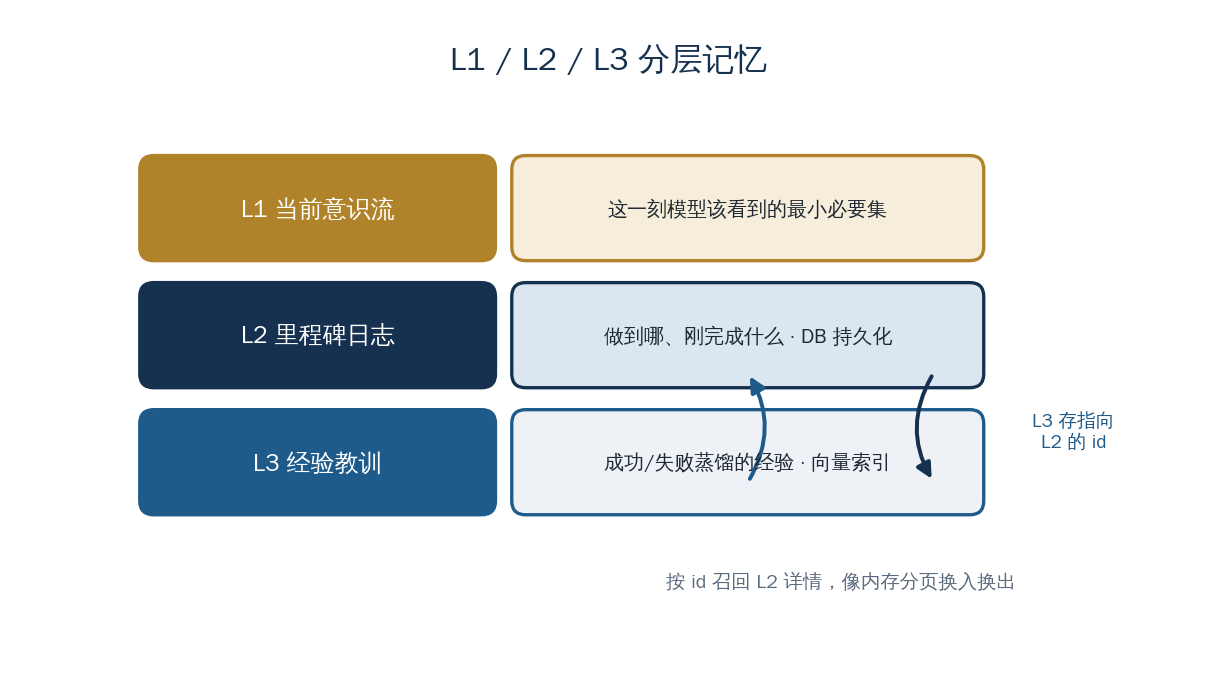
执行型 Agent 要在企业级场景里持续工作,光有当下这一轮的上下文不够,还得有一套记忆体系把不同时效、不同用途的信息分开存放。东方屹腾把记忆分成三层。L1 是当前意识流,也就是这一刻模型该看到的最小必要集,是当前推理或回复的直接输入。L2 是里程碑日志,记录做到哪、刚完成了什么,结构化地持久化在数据库里。L3 是经验教训,在一次任务成功或失败时,对当时的叙事上下文蒸馏总结后产出,存进向量库,用嵌入做语义索引。三层各管一段时效:L1 是眼前,L2 是这次任务的轨迹,L3 是跨任务沉淀下来的经验。
使用说明
这套分层最值得讲清楚的,是 L3 和 L2 之间的衔接方式,它借用了操作系统内存分页的思路。L3 存的是语义摘要,体量小、便于按语义检索;但摘要省去了细节,真要复盘某段经验当时的具体情形,光有摘要不够。所以 L3 的数据结构里会保存一个指向 L2 原始记忆事实的 id:平时只带着轻量的摘要在向量库里待命,需要原始详情时,再用这个 id 去 L2 把完整事实召回。这正是操作系统内存分页换入换出的一次具体实现——常驻的是摘要,原始详情按需加载。
它要避免的是两类相反的浪费。一类是把全部历史细节都常驻在上下文里,链路一长就会超出 prompt 的容量上限、推高每一步的成本。另一类是为了节省上下文把经验压成摘要,结果丢失了复盘所需的原始事实。分页式的存取在两者之间取得平衡:检索时只走轻量摘要,原始详情按 id 按需读取。
东方屹腾的薪资组搭建场景里能看到 L3 怎么帮上忙。如果某个场景之前已经发现用哪个技能能解决,这次推理就能凭一段相似的经验很快收敛,相当于一次似曾相识的同类任务检验。反过来,如果之前某个中间环节的接口调用失败过,这次任务规划就可以先调一个健康检查接口、确认那个 API 已经恢复,再编排后面的执行,免得重量级场景的前序任务白白跑一遍。这里还有一条落地纪律:L3 召回成本高,不要每一步推理都召回,只在大的推理入口处召回——链式推理的首次推理、ReAct 的首次推理、执行任务规划时。这些是最需要全面参考信息的入口环节,第一步在更完整的信息下做对了,后续环节就更容易跟着走对。
何时需要
当你的 Agent 要跨任务积累经验、又不想让历史细节把每一步的上下文撑爆时,就需要把记忆按时效和用途分层,让轻量摘要常驻、原始详情按需召回。它的摘要来自锚、账、集里那份不断蒸馏的进展,而每一步真正注入给模型的那一包,由记忆信封负责组装。